Loading... # [编程中常用的字符编码知识点](https://mp.weixin.qq.com/s/i4gDPLtDqZ3XST18LrXQEw)  **字符集和字符编码** -------------- 字符集就是字符的集合,如常见的 ASCII字符集,GB2312字符集,Unicode字符集等。这些不同字符集之间最大的区别是所包含的字符数量的不同。 字符编码则代表字符集的实际编码规则,是用于计算机解析字符的,如 GB2312,GBK,UTF-8 等。字符编码的本质就是如何使用二进制字节来表示字符的问题。 字符集和编码是一对多的关系,同一字符集可能有多种字符编码,如Unicode字符集就有 UTF-8,UTF-16 等。 在前端开发中,Javascript程序是使用Unicode字符集,Javascript源码文本通常是基于UTF-8编码。 但js代码中的字符串类型是UTF-16编码的,这也是为什么会碰到api接口返回字符串在前端出现乱码,因为多数服务都使用utf-8编码,前后编码方式不一致。 说起字符集的发展历程,可以总结为一句话:几乎都是对ASCII字符集的扩展。 **ASCII** -------------= 我们知道,计算机是使用二进制来处理信息的。 其中,每一个二进制位(bit)有 0和1 两种状态。一个字节(byte)则有8个二进制位,可以有256种状态。 而ASCII就是基于拉丁字母、主要用于显示英文的一种单字节字符集,它的编码和字符是一一对应的,因为它就是使用一个字节8个二进制位来表示,不会超过256个字符。 标准的ASCII字符总计有128个字符(2^7),其中前面32个控制字符,后面96个是可打印字符,包括常用的大小写字母数字标点符号等。因为只占用了一个字节的后7位,那字节的最高位一般设置为0。 ``` 'a'.charCodeAt() // 97 'A'.charCodeAt() // 65 '9'.charCodeAt() // 57 '.'.charCodeAt() // 46 ``` 如上,每个字符会对应一个编码(使用数字标识),总共会从0-128。完整的ASCII码表,网上很容易找到。 通过ASCII码表,我们发现,小写字母并没有和大写字母挨着排序?这是为了方便大小写之间的转换, A 排在 65(64 + 1) 位,而 a 排在 97(64 + 32 + 1) 位。 ``` 65 ^ 32 = 97 // A ^ 32 = a ``` 字符集的发展历史 ------------- ASCII是几乎所有字符集的基础。 标准的ASCII码最多只能标识128个字符,欧美国家可以很好的使用,但其他国家的字符变多,自然就不够用了。 这个时候,最高位就开始被惦记上,通过扩展ASCII码的最高位,又能满足用于特殊符号的一些国家的需求,这种就是扩展ASCII码。 但是亚非拉更多非拉丁语系的国家,字符成千上万,只能使用新的方式。 如中文,就又进行了扩展,小于127的字符的意义与标准ASCII码相同,当需要标识汉字时,使用2个字节,每个字节都大于127。这种多字节字符集即GB2312,后续因为不断的扩展,如繁体字和各种符号,甚至少数民族的语言符号等等,又使用了包括GBK等不同字符集。 因此,很多国家都制定了自己的编码字符集,基本都是在ASCII的基础上进行的。 各字符集虽然都能够兼容标准ASCII码,但在使用交流上的不便是显而易见的,乱码也是随处可见。为了解决这种各自为战的问题,Unicode字符集就诞生了。 Unicode ------------ Unicode是国际组织制定的,用于收纳世界上所有文字和符号的字符集方案。 前128个字符同ASCII一样,进行扩充后,使用数字0-0x10FFFF来映射这些字符,最多可以有1114112个字符。目前仍然只使用了其中的一小部分。 Unicode一般使用两个字节来表示一个字符。 * 码点 Unicode 规定了每个字符的数字编号,这个编号被称为 码点(code point)。码点以 U+hex 的形式表示,U+是代表Unicode的前缀,而 hex 是一个16进制数。取值范围是从 U+0000 到 U+10FFFF。 每个码点对应一个字符,绝大部分的常见字符在最前面的 65536 个字符,范围是 U+0000到U+FFFF。 一般汉字的码点区间为 U+2E80 - U+9FFF。 * 字符平面 目前的Unicode分成了17个编组,也称平面,每个平面有65536个码点。第一个平面是基本多语言平面,范围:U+0000 - U+FFFF,多数常见字符都在该区间。其他平面则为辅助平面,范围:U+10000 到 U+10FFFF,如我们在网上常见 Emoji 表情。 * 码元 码元(Code Unit)可以理解为对码点进行编码时的最小基本单元,码元是一个整体。而字符编码的作用就是将Unicode码点转换成码元序列。Unicode常用的编码方式有 UTF-8 、UTF-16 和 UTF-32,UTF是Unicode TransferFormat的缩写。UTF-8是8位的单字节码元,UTF-16是16位的双字节码元,UTF-32是32位的四字节码元。 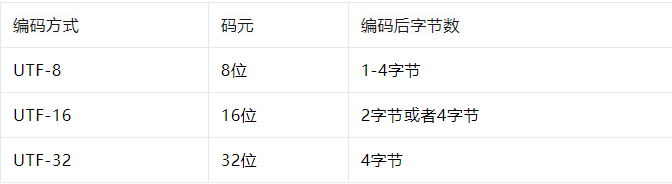 另外,为什么总看到使用十六进制数据来表示如码点等各种数据呢? 因为,两位的十六进制正好等于一个字节8位,0xff = 0b11111111。 UTF-8 --------- UTF-8是一种可变长度的字符编码方式。目前是使用 1 到 4 个字节来编码字符;是互联网时代应用最广的一种编码方式,前端接触的相对最多。 需要注意的是:汉字一般占3个字节,表情符号一般占4个字节。 UTF-8的编码规则: * 1个字节的字符,第一位为0,后7位为码点,与ASCII相同。 * n个字节的字符,第一个字节前面 n 位都是1,n+1位是0,可据此判断有几个字节。后面的几个字节都是 10 为开头2位。 这里规定的都是前缀,对于字符的码点,需要进行截取后依次放入除前缀外的其他位,所以UTF-8又被称为前缀码。格式如表:  通过上表的编码规则,我们就可以进行各种转换了。 下面,我们以一个中文字符的编码转换为例,如汉字 '好': > '好'的Unicode码点:'好'.codePointAt() \\\ 22909,结果是22909; > 22909在UTF-8的3字节数的编码区间 U+0800 (2048) ~ U+FFFF (65535); > 22909的二进制值:101100101111101,有15位; > 而3字节数的编码需要16位,前面补0,根据表中规则分成3组:0101 100101 111101; > 依次填入对应的前缀:11100101 10100101 10111101,得到3个字节; > 将得到的三个字节转成十六进制数据:E5 A5 BD,所以汉字 '好' 的UTF-8就是:E5 A5 BD。 我们使用 encodeURI 进行验证——encodeURI函数支持将中文进行 UTF-8 编码: ``` encodeURI('好') // '%E5%A5%BD' ``` 去除百分号,结果正好一致。 UTF-16 ---------- UTF-16的编码方式:基本平面的字符占用 2 个字节(U+0000到U+FFFF),辅助平面的字符占用 4 个字节(U+010000到U+10FFFF)。 也就是说,UTF-16的编码长度要么是2个字节要么是4个字节。当为2字节时,则实际上与Unicode相同。 并且还有个原则,在Unicode基本多语言平面内,从U+D800到U+DFFF之间的码点区间是不对应字符的。而UTF-16需要利用这块码位来对辅助平面的字符进行编码。 它的具体规则: * 码点小于U+FFFF,基本字符,不需处理,直接使用,占两个字节。 * 否则,拆分成两个码元,四个字节,cp表示码点:低位——((cp - 65536) / 1024) + 0xD800,值范围是 0xD800~0xDBFF;高位——((cp - 65536) % 1024) + 0xDC00,值范围是 0xDC00~0xDFFF。 看下面的示例: > 汉字 '好','好'.codePointAt() // 22909,码点小于U+FFFF,直接进行十六进制转换:579D。表情符号 '',''.codePointAt() // 128516,码点需要拆分:低位:Math.floor(((128516 - 65536) / 1024)) + 0xD800 // 55357, 得到 D83D高位:((128516 - 65536) % 1024) + 0xDC00 // 56836,得到 DE04 使用 String.fromCharCode 方法进行验证: ``` String.fromCharCode(0xD83D, 0xDE04) // '' ``` 需要明确的一点,Javascript中的字符串是基于UTF-16编码的,大端序字节。 > UTF-32是定长的编码,每个码位使用四个字节进行编码。优点是和unicode一一对应,缺点是太浪费空间。 比较 ------ 下面将选取字母、汉字、表情字符,进行编码对比查看: ``` // UTF-8 'a': 97 - 0x61 '好': 22909 - (0xE5 0xA5 0xBD) '': 128516 - (0xF0 0x9F 0x98 0x84) // UTF-16 'a': 97 - 0x0061 '好': 22909 - 0x597d '': 128516 - (0xD83D, 0xDE04) ``` 可以看到,UTF-8是变长1-4个字节,码元为8位;UTF-16是2或4字节,码元是16位。 这里记住UTF-16的码元,对于我们理解下面的问题,比较有帮助。 前端开发中的编码 ------------- 前面已提到过,javascript中的字符串是基于UTF-16编码的,所以在计算字符串长度时,我们需要先理解UTF-16编码。 下面,我们看一下处理字符串时可能会遇到的问题。 字符串长度计算 ------------ 字符串的length属性,实际上是使用UTF-16的码元个数来进行计算的: * ASCII码和大部分中文,都是一个码元 * 而表情字符和其他特殊字符都是两个码元 所以,当某个字符中存在2个码元时,就算显示的是一个字符,length却等于2。 ``` 'a'.length // 1 '好'.length // 1,多数汉字都是基本字符平面,只有一个码元,长度就为1。 ''.length // 2 ``` 组合字符的长度 ------------ 还有一种特殊的,组合字符,一般指一些带标点符号的字符:é。 ``` 'é'.length // 2 'e\u0301'.length // 2 // 获取码点时,忽略了标点符号,显示的是字母的码点 'é'.codePointAt() // 101 'e'.codePointAt() // 101 ``` 如要正常操作组合字符,使用normalize()。 ``` 'é'.normalize().length = 1。 ``` 多码元字符操作 ------------ 对于多码元字符使用下标取值时,得到的将是它的码元: ``` ''[0] // '\uD83D' ''[1] // '\uDE04' '123'[0] // '1' ``` 循环时,使用 for 会乱码,而 for-of 则正常: ``` let smile = '' for(let i = 0; i < smile.length; i++) { console.log(smile[i]) } // � // � for (let tt of smile) { console.log(tt) } // ``` 但是,可以使用转换成扩展数组的方式访问: ``` [...''][0] // '' Array.from('') // [''] ``` 还可以使用码点的方式: ``` String.fromCodePoint(''.codePointAt()) // '' ``` 对于这种特殊字符,使用下面的字符串方法都会分割码元: split(),slice(),charAt(),charCodeAt(),substr(),substring()。 ``` ''.slice(0, 2) // '' ''.slice(0, 1) // '\uD83D' ''.slice(1, 2) // '\uDE04' ''.substr(0,1) // '\uD83D' ''.substr(0,2) // '' ''.split('') // ['\uD83D', '\uDE04'] ``` 正则中的 u 修饰符 ----------------- ES6在正则中添加了u修饰符,用来正确处理大于\\uFFFF的 Unicode 字符,也就是能够正确处理四个字节的 UTF-16 编码。 ``` /^\S$/.test('') // false /^\S$/u.test('') // true ``` 但对组合字符,u修饰符不起作用: ``` /^\S$/u.test('é') // false /^\S$/u.test('e\u0301') // false ``` 转义字符 ------ 我们还需要注意的,是转义字符的计算,结果会以实际字符为准: ``` '\x3f'.length // 1 '?'.length // 1 ``` 读取操作时,也能正常处理: ``` '\x3f'[0] // '?' '\x3f'.split('') // ['?'] ``` 常用API --------- 前端在对Unicode编码处理时,提供了一些可以使用的API,在实际工作中,会方便我们处理这方面的问题。 处理码点和字符 ------------ * charAt(index) 从一个字符串中返回指定的字符,对于多码元字符,仍会返回码元字符: ``` 'a'.charAt() // 'a' ''.charAt() // '\uD83D' ''.charAt(1) // '\uDE04' ``` * charCodeAt(index) 返回0到65535之间的整数码点值。对于多码元如果字符的码点大于U+FFFF,则返回第一个码元值,还可以加索引参数取后面码元的值。 * codePointAt(pos) 返回Unicode码点,多码元也能返回完整的码点值。codePointAt可以传入索引参数,对多码元字符取第二个码元值。 ``` // 小于 U+FFFF '好'.codePointAt() // 22909 '好'.charCodeAt() // 22909 // 大于 U+FFFF ''.charCodeAt() // 55357 ''.charCodeAt(1) // 56836 ''.codePointAt() // 128516 ''.codePointAt(1) // 56836 ``` * String.fromCharCode(num1\[, ...\[, numN\]\]) 返回由指定的UTF-16码点序列创建的字符串。参数范围0到65535,大于65535的数据将被截断,结果不准确。对于多码元字符,则会将两个码元组合得到该字符。 * String.fromCodePoint(num1\[, ...\[, numN\]\]) 返回使用指定的代码点序列创建的字符串。可以处理多码元字符的完整码点值。 ``` String.fromCharCode(55357, 56836, 123) // '{' String.fromCodePoint(128516, 123, 8776) // '{≈' ``` TextEncoder ------------- TextEncoder,使用 UTF-8 编码将代码点流转换成字节流。 TextDecoder:解码。 默认编码方式就是UTF-8,可以解决字符转UTF-8编码的问题。 ``` const txtEn = new TextEncoder() const enVal = txtEn.encode('好') // Uint8Array(3) [229, 165, 189] const txtDe = new TextDecoder() txtDe.decode(enVal) // '好' ``` IE不支持。 String.prototype.normalize() ------------- 对于语调符号和重音符号,Unicode提供了两种方法,一种是直接提供带符号的字符,如 é (码点233);另一种是组合字符,如上文提到的 é (码点101)。 针对这种码点不同,但实质一样的字符,Javascript识别不了: ``` 'é' === 'é' // false ``` 而 normalize() 方法的引入,正是为了解决这一问题,它会按照一定的方式将字符的不同表示方法统一为标准形式: ``` 'é' === 'é'.normalize() // true ``` URL的UTF8编解码 ------------- 另外,在前端常接触的网页中,URL链接编码也是非常常见的。诸如:'http%3A%2F%2Fbaidu.com%2F%E4%B8%AD%E5%9B%BD'。这里面涉及到的就是关于UTF-8的编码。 而JavaScript提供了四个URL的编码/解码方法,可以用于将非ASCII码的字符,如中文字符、特殊字符、表情字符等,进行UTF-8的编解码操作: * encodeURI() 和 encodeURIComponent() * decodeURI() 和 decodeURIComponent() 他们的短处也很明显,对ASCII字符如英文数字等字符无法处理。 这里的转换方式:先转为UTF-8的字节码,然后前面加个 % 进行拼接得到编码结果。 ``` encodeURI('好') // '%E5%A5%BD' decodeURI('%E5%A5%BD') // '好' encodeURIComponent('好') // '%E5%A5%BD' decodeURIComponent('%E5%A5%BD') // '好' encodeURI('hello') // 'hello' encodeURIComponent('hello') // 'hello' encodeURIComponent('') // '%F0%9F%98%84' ``` encodeURI和encodeURIComponent的区别 ------------------ 这两者的不同之处,在于对部分URL元字符符号的处理上。 > URL元字符:分号(;),逗号(’,’),斜杠(/),问号(?),冒号(:),at(@),&,等号(=),加号(+),美元符号($),井号(#)。 encodeURIComponent会对这些URL元字符进行编码,但是encodeURI则不会: ``` encodeURIComponent(';,/@&=') // '%3B%2C%2F%40%26%3D' encodeURI(';,/@&=') // ';,/@&=' ``` END ****作者:土豆居士**** ****来源:一口Linux**** * * * 版权归原作者所有,如有侵权,请联系删除。 最后修改:2023 年 12 月 05 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏